
Crawling the Queer Web
TransArchive seeks to index and archive as much information that is critical to trans and LGBTQIA+ people as possible. The article reflects on some of the lessons learned during development.

I've talked previously about transarchive.eu, an attempt to locate and archive information that is important to the LGBTQIA+ community, and to trans people in particular. When the project started, I thought it might have ended up with maybe a couple of hundred human-curated sites, but this vision didn't last long when it met reality squarely in the face.
When I started digging into the problem, the numbers didn't add up. Firstly, supporting of the order of a couple of hundred sites wouldn't remotely scratch the surface. Secondly, the overhead of manual curation and moderation was, even at that scale, impractical. Though I might be OK with spending a few hours at a time going through URLs and writing listings for them, I timed myself and did the math. I also asked my long-suffering spouse to have a go too, and I timed them too. Though they were enthusiastic in principle, they lasted about 20 minutes and drifted off to do something else. I couldn't really blame them – it was hard work and not really fun, particularly when you end up having to read the kind of material that, as a trans person, is extremely corrosive to your wellbeing. Even then, with a modest scale-up to 1000 supported sites, I figured out that this would require hundreds of volunteers donating an hour or so each week even to make some kind of headway.
The phenomenon that human moderation can be damaging is well known. The classic example, widely understood but not really talked about much in the industry, is that of material representing abuse – CSAM is the worst of this, but it's certainly not the only problematic case. Human moderators don't last long, and often end up with psychological damage. Though in our case we are less likely to encounter the more extreme material, since many (if not most?) trans people have suffered abuse themselves, exposing them (our pool of volunteer moderators) to anti-trans material would not be acceptable.
It is common in the industry to use AI for this – indeed, this kind of approach was widely used long before LLMs appeared, and has been extremely successful. Though many of us have had posts rejected because of the occasional error, this is a very small price to pay relative to the real human cost that would have been the consequence of not doing this.
After some experimentation, the TransArchive web crawler now uses three machine learning models:
- A small, very fast, lightweight model whose purpose is, given a web page, to decide whether it contains human-readable text at all, and if so, in what language. Currently we don't do anything special with the language other than log it for later use, but eventually this will be useful for making TransArchive properly multilingual.
- A full-strength LLM configured to analyze the text on a page to decide whether it talks about something relevant to trans and/or LGBTQIA+ people.
- A second instance of that same model configured to summarize the page, generating a category, title and description for inclusion in the index.
With a bit of experimentation, I managed to get this to work pretty well. The way the crawler works is it first pulls the contents of a URL, identifies its contents, and if it contains human-readable text with high probability, it analyzes the page to see whether it is of interest. If it is, the model is used a second time to generate the category, title and description. The results aren't perfect – they do need a bit of human fixup sometimes, and occasionally they mess up completely, but in a very high percentage of cases the results are directly usable. Running on a single NVIDIA RTX6000 GPU, this gives 2 or 3 new entries in the database per minute. Only pages that survive this process have their outgoing links added to the database – this hopefully guides the system toward only crawling parts of the web that are directly interesting.
I started wondering whether this is actually sufficient. Will this actually crawl the entire queer web?
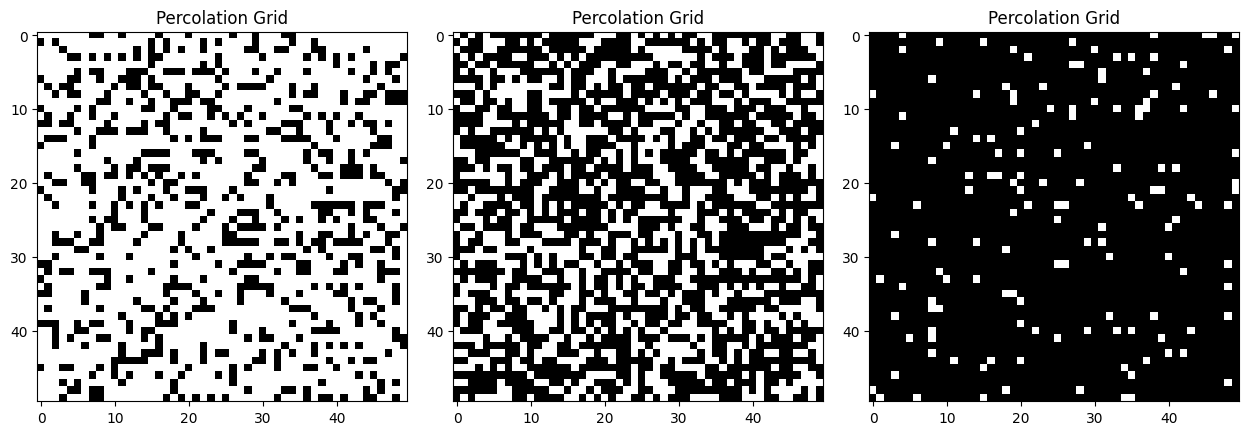
Some very old mathematics can help answer this. Percolation theory deals with what happens when you have a large number of interconnected nodes that are connected to other nodes with a particular probability. As a very simplistic example, imagine an (arbitrarily large) square grid, with squares coloured black with a particular probability. In the illustration above, the left grid has black squares with a probability of 0.3 (i.e., on average 3 squares in 10 are black). If you pick a black square and see how far you can get by only stepping on adjacent black squares, you can't get very far before you run out of black squares. These disconnected groups are typically called closed clusters in the literature. Compare this to the grid on the right, where nearly all (95%) of squares are coloured black. Here, you can go more or less anywhere you like, and if the grid continued like that forever, you could most likely keep walking forever without running out of black squares. Such clusters are typically called open clusters. The one in the middle is the most interesting – it's right at the critical point between clusters being primarily open and primarily closed. Plotting probability against the likelihood of an open cluster being present looks like this:
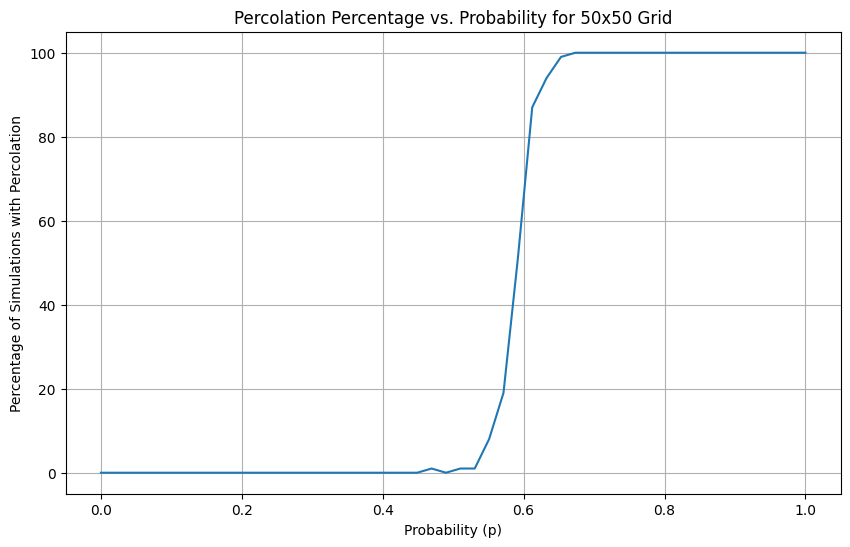
Something that is interesting about this is the slope of the curve is always pretty steep, and the point at which it passes 50% (the critical probability) is quite consistent for any underlying system with the same kind of connectivity.
Taking this idea and dropping it in the middle of the need to crawl the web, it's pretty clear that web pages are way more interconnected than a 2d grid, even if we only expand nodes that are of direct interest. I don't have enough stats (yet?) to run a simulation, but it seems pretty likely that our slice of the web is indeed an open cluster in its own right.
All this said, the web is big, and it will take a long time to crawl everything of interest. It may not even be possible to crawl everything without scaling up our infrastructure to an absurd level – we're not trying to be Google Search, Bing or Duck Duck Go. Therefore, it is still useful to have a suggest URL option on the web site, because even though the crawler will probably eventually hit every site of interest, it would be more useful to get to the best ones sooner.
All this said, TransArchive is still an ongoing project. It will get more tweaks in the future, both to the UI and with respect to improving data quality, though it's now at a point where it won't be my 100% focus for a while. If anyone wants to contribute to cleaning up the data, ping me, and I can potentially add you as a (human) moderator. Eventually, when the database is big enough and enough cleanup has been done, I would like to have a go at fine-tuning the models so they do a slightly more consistent job, but this will take 50k - 100k examples, and we're nowhere close yet.