
Datacenters in space are a terrible, horrible, no good idea.
There is a rush for AI companies to team up with space launch/satellite companies to build datacenters in space. TL;DR: It's not going to work.

In the interests of clarity, I am a former NASA engineer/scientist with a PhD in space electronics. I also worked at Google for 10 years, in various parts of the company including YouTube and the bit of Cloud responsible for deploying AI capacity, so I'm quite well placed to have an opinion here.
The short version: this is an absolutely terrible idea, and really makes zero sense whatsoever. There are multiple reasons for this, but they all amount to saying that the kind of electronics needed to make a datacenter work, particularly a datacenter deploying AI capacity in the form of GPUs and TPUs, is exactly the opposite of what works in space. If you've not worked specifically in this area before, I'll caution against making gut assumptions, because the reality of making space hardware actually function in space is not necessarily intuitively obvious.
Power

The first reason for doing this that seems to come up is abundant access to power in space. This really isn't the case. You basically have two options: solar and nuclear. Solar means deploying a solar array with photovoltaic cells – something essentially equivalent to what I have on the roof of my house here in Ireland, just in space. It works, but it isn't somehow magically better than installing solar panels on the ground – you don't lose that much power through the atmosphere, so intuition about the area needed transfers pretty well. The biggest solar array ever deployed in space is that of the International Space Station (ISS), which at peak can deliver a bit over 200kW of power. It is important to mention that it took several Shuttle flights and a lot of work to deploy this system – it measures about 2500 square metres, over half the size of an American football field.
Taking the NVIDIA H200 as a reference, the per-GPU-device power requirements are on the order of 0.7kW per chip. These won't work on their own, and power conversion isn't 100% efficient, so in practice 1kW per GPU might be a better baseline. A huge, ISS-sized, array could therefore power roughly 200 GPUs. This sounds like a lot, but lets keep some perspective: OpenAI's upcoming Norway datacenter is intending to house 100,000 GPUs, probably each more power hungry than the H200. To equal this capacity, you'd need to launch 500 ISS-sized satellites. In contrast, a single server rack (as sold by NVIDIA preconfigured) will house 72 GPUs, so each monster satellite is only equivalent to roughly three racks.
Nuclear won't help. We are not talking nuclear reactors here – we are talking about radioisotope thermal generators (RTGs), which typically have a power output of about 50W - 150W. So not enough to even run a single GPU, even if you can persuade someone to give you a subcritical lump of plutonium and not mind you having hundreds of chances to scatter it across a wide area when your launch vehicle explosively self-disassembles.
Thermal Regulation
I've seen quite a few comments about this concept where people are saying things like, "Well, space is cold, so that will make cooling really easy, right?"
Um...
No.
Really, really no.
Cooling on Earth is relatively straightforward. Air convection works pretty well – blow air across a surface, particularly one designed to have a large surface area to volume ratio like a heatsink, will transfer heat from the heatsink to the air quite effectively. If you need more power density than can be directly cooled in this way (and higher power GPUs are definitely in that category), you can use liquid cooling to transfer heat from the chip to a larger radiator/heatsink elsewhere. In datacenters on Earth, it is common to set up cooling loops where machines are cooled via chilled coolant (usually water) that is pumped around racks, with the heat extracted and cold coolant returned to the loop. Typically the coolant is cooled via convective cooling to the air, so one way or another this is how things work on Earth.
In space, there is no air. The environment is close enough to a hard, total vacuum as makes no practical difference, so convection just doesn't happen. On the space engineering side, we typically think about thermal management, not just cooling. Thing is, space doesn't really have a temperature as-such. Only materials have a temperature. It may come as a surprise, but in the Earth-Moon system the average temperature of pretty much anything is basically the same as the average temperature of Earth, because this is why Earth has that particular temperature. If a satellite is rotating, a bit like a chicken on a rotisserie, it will tend toward having a consistent temperature that's roughly similar to that of the Earth surface. If it isn't rotating, the side pointing away from the sun will tend to get progressively colder, with a limit due to the cosmic microwave background, around 4 Kelvin, just a little bit above absolute zero. On the sunward side, things can get a bit cooked, hitting hundreds of centigrade. Thermal management therefore requires very careful design, making sure that heat is carefully directed where it needs to go. Because there is no convection in a vacuum, this can only be achieved by conduction, or via some kind of heat pump.
I've designed space hardware that has flown in space. In one particular case, I designed a camera system that needed to be very small and lightweight, whilst still providing science-grade imaging capabilities. Thermal management was front and centre in the design process – it had to be, because power is scarce in small spacecraft, and thermal management has to be achieved whilst keeping mass to a minimum. So no heat pumps or fancy stuff for me – I went in the other direction, designing the system to draw a maximum of about 1 watt at peak, dropping to around 10% of that when the camera was idle. All this electrical power turns into heat, so if I can draw 1 watt only while capturing an image, then turn the image sensor off as soon as the data is in RAM, I can halve the consumption, then when the image has been downloaded to the flight computer I can turn the RAM off and drop the power down to a comparative trickle. The only thermal management needed was bolting the edge of the board to the chassis so the internal copper planes in the board could transfer any heat generated.
Cooling even a single H200 will be an absolute nightmare. Clearly a heatsink and fan won't do anything at all, but there is a liquid cooled H200 variant. Let's say this was used. This heat would need to be transferred to a radiator panel – this isn't like the radiator in your car, no convection, remember? – which needs to radiate heat into space. Let's assume that we can point this away from the sun.
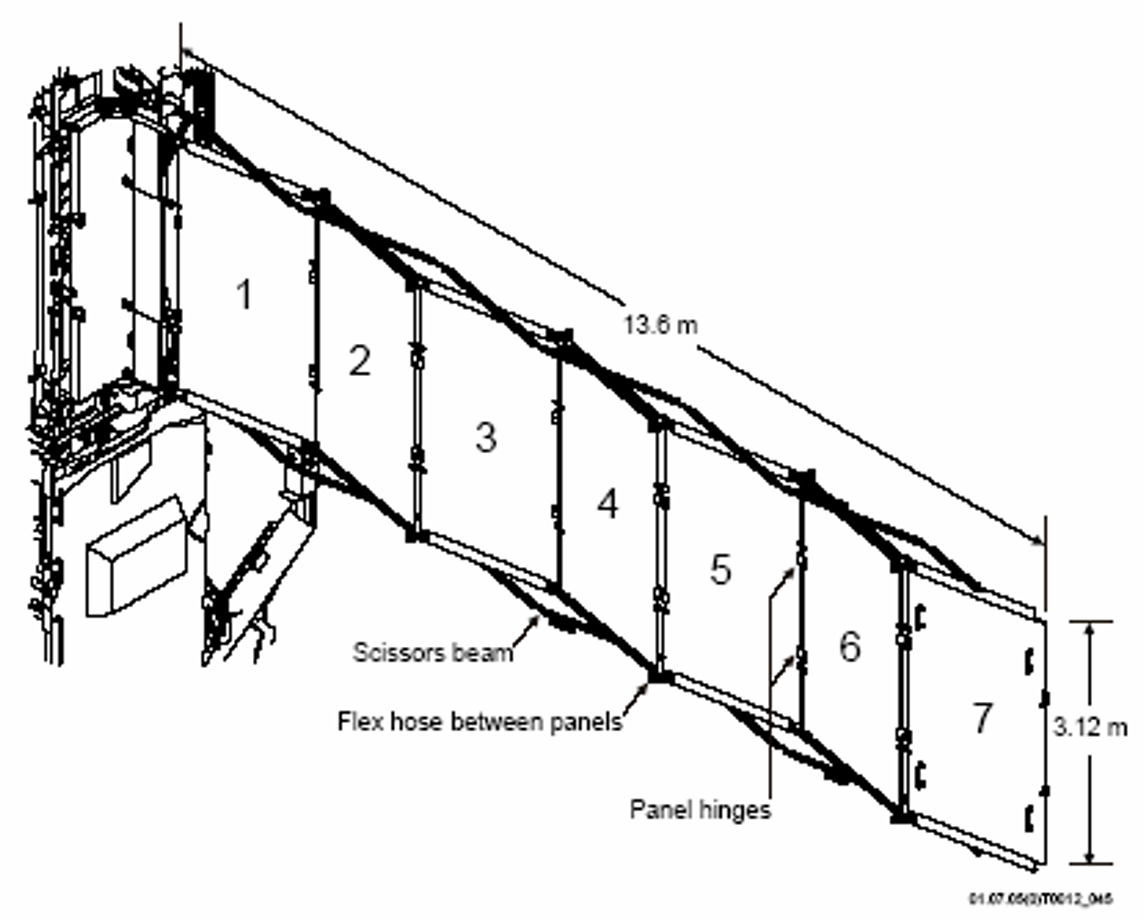
The Active Thermal Control System (ATCS) on the ISS is an example of such a thermal control system. This is a very complex system, using an ammonia cooling loop and a large thermal radiator panel system. It has a dissipation limit of 16kW, so roughly 16 H200 GPUs, a bit over the equivalent to a quarter of a ground-based rack. The thermal radiator panel system measures 13.6m x 3.12 m, i.e., roughly 42.5 square metres. If we use 200kW as a baseline and assume all of that power will be fed to GPUs, we'd need a system 12.5 times bigger, i.e., roughly 531 square metres, or about 2.6 times the size of the relevant solar array. This is now going to be a very large satellite, dwarfing the ISS in area, all for the equivalent of three standard server racks on Earth.
Radiation Tolerance
This is getting into my PhD work now. Assuming you can both power and cool your electronics in space, you have the further problem of radiation tolerance.

The first question is where in space?
If you are in low Earth orbit (LEO), you are inside the inner radiation belt, where radiation dose is similar to that experienced by high altitude aircraft – more than an airliner, but not terrible. Further out, in mid Earth orbit (MEO), where the GPS satellites live, they are not protected by the Van Allen belts – worse, this orbit is literally inside them. Outside the belts, you are essentially in deep space (details vary with how close to the Sun you happen to be, but the principles are similar).
There are two main sources of radiation in space – from our own star, the Sun, and from deep space. This basically involves charged particles moving at a substantial percentage of the speed of light, from electrons to the nuclei of atoms with masses up to roughly that of oxygen. These can cause direct damage, by smashing into the material from which chips are made, or indirectly, by travelling through the silicon die without hitting anything but still leaving a trail of charge behind them.
The most common conseqence of this happening is a single-event upset (SEU), where a direct impact or (more commonly) a particle passing through a transistor briefly (approx 600 picoseconds) causes a pulse to happen where it shouldn't have. If this causes a bit to be flipped, we call this a SEU. Other than damage to data, they don't cause permanent damage.
Worse is single-event latch-up. This happens when a pulse from a charged particle causes a voltage to go outside the power rails powering the chip, causing a transistor essentially to turn on and stay on indefinitely. I'll skip the semiconductor physics involved, but the short version is that if this happens in a bad way, you can get a pathway connected between the power rails that shouldn't be there, burning out a gate permanently. This may or may not destroy the chip, but without mitigation it can make it unusable.
For longer duration missions, which would be the case with space based datacenters because they would be so expensive that they would have to fly for a long time in order to be economically viable, it's also necessary to consider total dose effects. Over time, the performance of chips in space degrades, because repeated particle impacts make the tiny field-effect transistors switch more slowly and turn on and off less completely. In practice, this causes maximum viable clock rates to decay over time, and for power consumption to increase. Though not the hardest issue to deal with, this must still be mitigated or you tend to run into a situation where a chip that was working fine at launch stops working because either the power supply or cooling has become inadequate, or the clock is running faster than the chip can cope with. It's therefore necessary to have a clock generator that can throttle down to a lower speed as needed – this can also be used to control power consumption, so rather than a chip ceasing to function it will just get slower.
The next FAQ is, can't you just use shielding? No, not really, or maybe up to a point. Some kinds of shielding can make the problem worse – an impact to the shield can cause a shower of particles that then cause multiple impact at once, which is far harder to mitigate. The very strongest cosmic rays can go through an astonishing amount of solid lead – since mass is always at a premium, it's rarely possible to deploy significant amounts of shielding, so radiation tolerance must be built into the system (this is often described as Radiation Hardness By Design, RHBD).
GPUs and TPUs and the high bandwidth RAM they depend on are absolutely worst case for radiation tolerance purposes. Small geometry transistors are inherently much more prone both to SEUs and latch-up. The very large silicon die area also makes the frequency of impacts higher, since that scales with area.
Chips genuinely designed to work in space are taped out with different gate structures and much larger geometries. The processors that are typically used have the performance of roughly a 20-year-old PowerPC from 2005. Bigger geometries are inherently more tolerant, both to SEUs and total dose, and the different gate topologies are immune to latch up, whilst providing some degree of SEU mitigation via fine-grained redundancy at the circuit level. Taping out a GPU or TPU with this kind of approach is certainly possible, but the performance would be a tiny fraction of that of a current generation Earth-based GPU/TPU.
There is a you-only-live-once (my terminology!) approach, where you launch the thing and hope for the best. This is commonplace in small cubesats, and also why small cubesats often fail after a few weeks on orbit. Caveat emptor!
Communications
Most satellites communicate with the ground via radio. It is difficult to get much more than about 1Gbps reliably. There is some interesting work using lasers to communicate with satellites, but this depends on good atmospheric conditions to be feasible. Contrasting this with a typical server rack on Earth, where 100Gbps rack-to-rack interconnect would be considered at the low end, and it's easy to see that this is also a significant gap.
Conclusions
I suppose this is just about possible if you really want to do it, but I think I've demonstrated above that it would firstly be extremely difficult to achieve, disproportionately costly in comparison with Earth-based datacenters, and offer mediocre performance at best.
If you still think this is worth doing, good luck, space is hard. Myself, I think it's a catastrophically bad idea, but you do you.